My Research
Current Work

Enhance RL with Noisy LLM Feedback
[EMNLP 2024]
Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models
[RLBrew Workshop, RLC 2024]
A Reward Analysis of Reinforcement Learning from Large Language Model Feedback
Extended RL from LLM Feedback to work well with small language models which may produce incorrect rankings:
- Proposed a potential-based reward specification method to scale down rewards based on LLM feedback uncertainty.
- Theoretically and empirically showed that uncertain LLM feedback leads to uninformative potential-based rewards, avoiding misleading rewards and enabling efficient training even with small error-prone LLMs.

AI-based Credit Assignment
Speaking the Language of Teamwork: LLM-Guided Credit Assignment in Multi-Agent Reinforcement Learning
In submission
Extended the error-tolerant RLAIF to multiagent collaboration tasks for credit assignment, decomposing team rewards to individual ones with LLM feedback.

Action Advising for Efficient RL in Ad Hoc Teaming
Enhancing Multi-Agent Teaming Efficiency Through Experience-Based Action Advising
In submission
Accelerated multiagent RL by enabling agents with different levels of prior competency to cooperate effectively in solving a shared task:
- Using a multi-armed bandit algorithm, the most experienced agent evaluated teammates' skills, assigned suitable sub-tasks, and adapted agents to these tasks via a policy advising algorithm, improving team learning and task efficiency.
Creative Mobile Robot Wall Painting
Implemented a mobile manipulator navigation framework for large-scale wall-painting. Integrated VLM models to enable image-to-stroke creative painting.Past Work
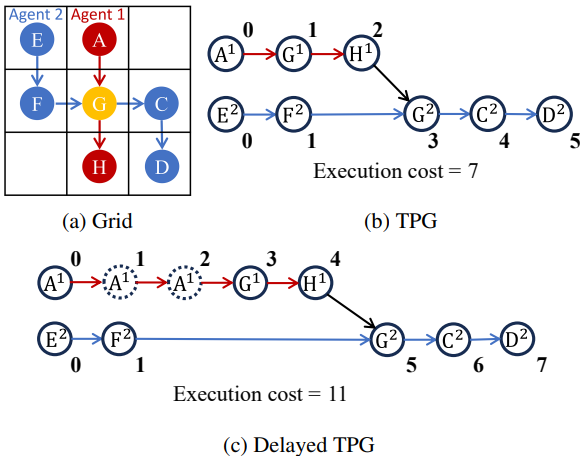
Addressing Unexpected Delays in Multi-agent Path Plan Execution
[AAAI 2025 (Oral)]
Speedup Techniques for Switchable Temporal Plan Graph Optimization
Optimizing a Switchable Temporal Plan Graph (STPG) is a common approach to handling unexpected delays in multi-agent path plan execution. We proposed acceleration techniques for this procedure, including stronger admissible heuristics, edge grouping, prioritized branching and incremental implementation.
- Achieved over 100% improvement in STPG reconstruction success rates within 0.5 seconds across maps with varying agent densities, outperforming Mixed-Integer Linear Programming and naive graph-based methods.
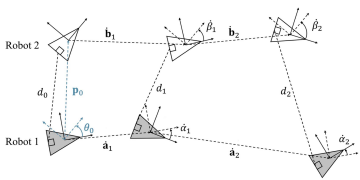
Multi-robot Relative Pose Estimation with Distance-measuring Units and Odometry Information
[Transactions on Mechatronics (TMECH) 2023]
Asymptotically Efficient Estimators for Range‑based Robot Relative Localization
Enhanced localization accuracy in multiagent systems, where robots communicated their odometry trajectories and relative distance with each other and then estimated their initial relative poses. Reduced the estimation residuals to the Cramer-Rao Lower Bound.

Active Feature Selection for Pose Estimation of Visual Odometry
Developed a quality measurement metric to select visual feature points for the multi-spectral odometry:
- Improved the accuracy of visual odometry pose estimation and efficiency (13.036% of the original residuals, 58.832% of the original CPU usage) with filtered visual feature points in dark environments.
